
記事要約
本記事では、PMBOK第8版が示すAI活用の考え方を踏まえ、
LLMに判断を委ねず、人が設計したポリシーと評価ロジックによってAIの振る舞いを制御する実装方法を、3つの検証を通じて整理しました。
検証では、組織AIポリシーとプロジェクトAIポリシーを分離し、制御レベル(HARD / CONDITIONAL)の違いが、評価結果やLLMの呼び出し有無にどのような影響を与えるかを確認しています。
その結果、AIの挙動は、人が設計した構造と評価ロジックによって一貫して制御できることが明らかになりました。
これにより、プロジェクトマネージャは、AIの業務実装における説明責任とどのように向き合うべきかについて、1つの方向性を見出すことができました。
本記事は、AI導入を「機能」ではなく「判断と責任の設計」として考えるための、実装視点の検討材料を提供します。
はじめに 三層AIポリシーを実際に検証してみる
下記の記事では、PMBOK第8版が示している AIポリシー(AI policies) の考え方を手がかりに、
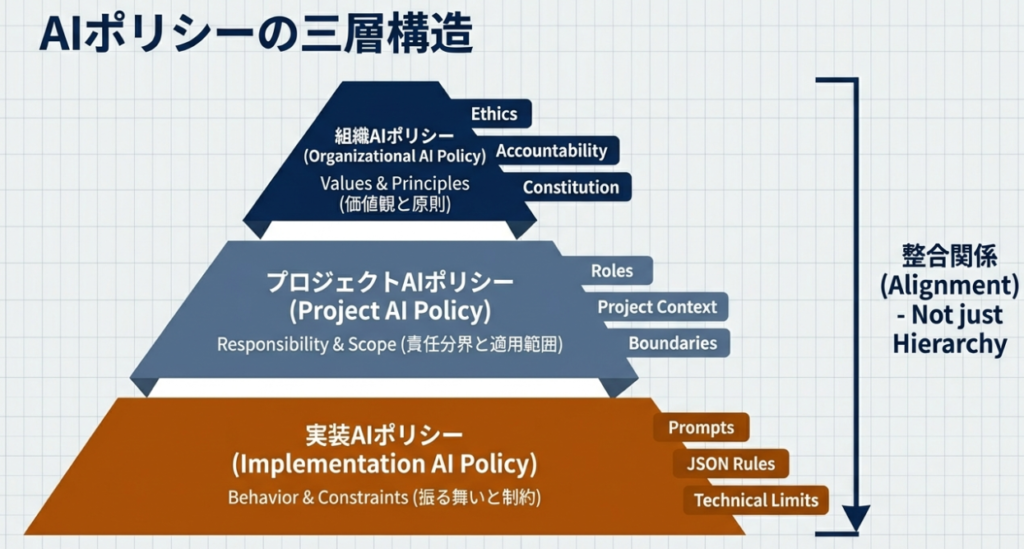
組織AIポリシー → プロジェクトAIポリシー → 実装AIポリシー という三層構造でAIを位置づけ、
それらを Gitによって管理する という実務的な整理を提案しました。

本稿の目的は、AIがどこまで賢く判断できるかを検証することではありません。
また、AIポリシーを AI 自身に解釈・判断させることの是非を論じるものでもありません。
本記事で扱うテーマは、より実務的で、より地味ではありますが重要な問いです。
説明責任を果たせる形で、AIを組織やプロジェクトの中に組み込むことは可能か。
そのとき、どこまでを AI に任せ、どこからを人が事前に定義すべきなのか。
この問いに対し、本稿では「AIに任せない判断領域を、意図的に切り出す」という立場を採用します。
具体的には、今回の検証においての前提を明記しておきます。
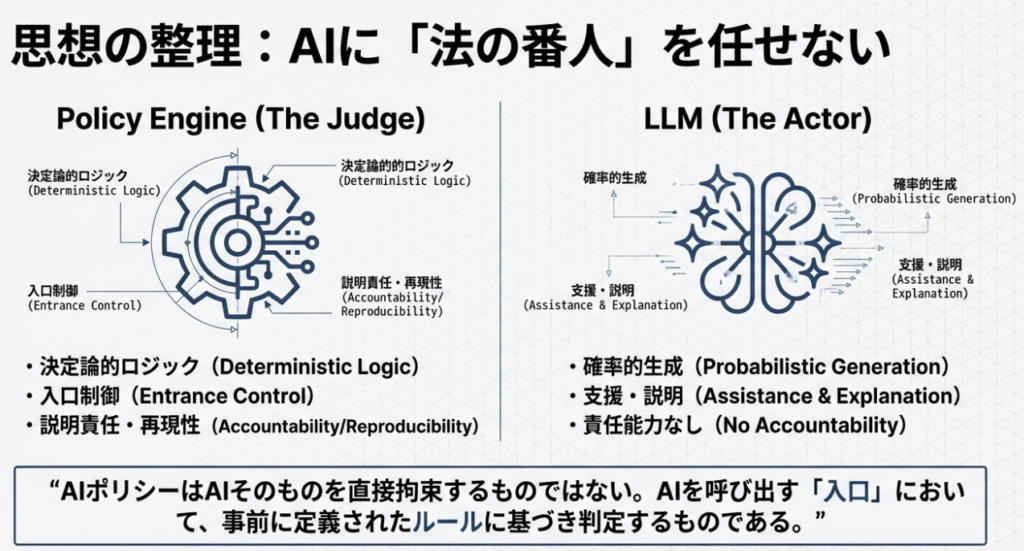
AIポリシーは AIそのものを直接拘束するものではありません
AIを呼び出す 入口(前段) において、
- 実行可否
- 制御レベルの優先順位
- ポリシー間の衝突
を判断します。
その判断は、AIではなく
事前に定義されたルールに基づくポリシーエンジン によって行います
これは、AIの能力を否定するための選択ではなく、説明責任・再現性・監査性が求められる判断を
AIに委ねないための、意図的な設計判断です。
本記事ではまず、
- 組織AIポリシー
- プロジェクトAIポリシー
を別ファイル・別管理とし、それらを統合的に評価する実装AIポリシー(ポリシーエンジンによる評価対象)という構造を整理します。
そのうえで、
- 制御レベルが異なる場合に、実際に何が起きるのか
- ポリシー間に矛盾や衝突があるとき、どのように振る舞うのか
- その挙動は、人が事前に説明可能な形になっているか
を、実行ログという「事実」をもとに検証していきます。
なお、本稿で示す検証結果は、特定の LLM の性能を評価するものではありません。
LLM が異なれば挙動が変わる可能性があることも、あらかじめ前提としています。
本検証の関心は一貫して、
AIを使うかどうかではなく、AIをどのように管理下に置くか
にあります。
本記事が、AIポリシーを“理念”ではなく運用可能な構造として考える一助になれば幸いです。
AIポリシーを三層に分けて考える
本検証では、AIポリシー構造とその解釈主体としてのLLMの関係性を観測することを目的としており、LLMが異なれば反応や説明が変わる可能性があることを、あらかじめ前提条件としています。
なぜAIポリシーを「一枚」で扱うと破綻するのか
AIポリシーという言葉は、しばしば一つの文書として扱われます。
しかし実務においては、次のような異なる性質のルールが混在しがちです。
- 組織として絶対に守るべき原則
- プロジェクトごとに調整される運用ルール
- 実装上、機械的に評価される条件分岐
これらを一つのポリシーとしてまとめてしまうと、
- 誰がそのルールを決めたのか
- どこまで裁量が許されているのか
- 変更した場合、どの範囲に影響が及ぶのか
が不明確になります。結果として、AIの挙動に対する説明責任を、人が負えなくなります。
この問題を避けるため、本記事ではAIポリシーを責務の異なる三層に分けて整理します。
組織AIポリシー 越えてはいけない一線を定義する
組織AIポリシーは、組織としての原則を定義するレイヤーです。
ここで扱うのは、
- 法令・コンプライアンス
- 個人情報や機密情報の取り扱い
- 組織として許容できないリスク
といった、プロジェクト単位では変更できない制約です。
本検証では、組織AIポリシーを専用の定義ファイルとして管理し、プロジェクト側が任意に書き換えられない前提を置いています。
このレイヤーの役割は、AIの利便性よりも組織としての説明責任と統制を優先することにあります。
プロジェクトAIポリシー 条件付きの裁量を与える
プロジェクトAIポリシーは、組織AIポリシーに準拠したうえで、
プロジェクト固有の判断や運用条件を定義するレイヤーです。
例えば、
- 特定用途に限ったAI利用
- プロジェクトマネージャ承認を前提とした例外的利用
- 期間・範囲を限定した条件付き許可
といった現実的な調整は、このレイヤーで扱います。
重要なのは、プロジェクトAIポリシーが組織AIポリシーを上書きするものではないという点です。
あくまで、上位ポリシーの範囲内で裁量を定義します。
実装AIポリシー ポリシーを「振る舞い」に変換する
実装AIポリシーは、人が定義したポリシーを、AI利用の可否という具体的な振る舞いへと変換するためのレイヤーです。組織AIポリシーとプロジェクトAIポリシーを入力として、実際のAIの挙動を決定するレイヤーです。
ここでは、
- どの条件でAI利用を許可するのか
- どの条件で処理を中断するのか
- その判断結果をどう記録・可視化するのか
が、機械的に評価されます。
実装AIポリシーは、独立した一枚の文書を指すものではありません。
複数のポリシー定義と、それを解釈・評価するロジックによって現れる挙動そのものを指します。
本検証では、この実装AIポリシーを通じて、
- AIがどのような条件で動作したのか
- その判断がどのポリシーに基づくものか
を追跡可能な形で可視化しています。
三層構造がもたらす意味
この三層構造によって、AIの利用に関して次のことが可能になります。
- AIの挙動を「AIの判断」としてではなく、人が設計したポリシー構造の結果として説明できる
- ポリシー変更の影響範囲を、事前に把握できる
- LLMが異なった場合でも、どこで判断が変わったのかを比較・評価できる
- ポリシー判断をAIに委ねる場合でも、どこまでをAIに任せ、どこを人が統制するかを切り分けられる
以降の章では、この三層構造を前提として、実際にポリシーを実装に落とし込んだ場合に何が起きたのかを検証していきます。
思想の整理・用語の定義・検証の前提共有
本章では、以降の検証を読み進めるうえで必要となる思想的な前提・用語の定義・検証条件を整理します。
ここで行う整理は、結論を導くためのものではありません。
あくまで、
- 何を検証しているのか
- 何を意図的に検証していないのか
を明確にし、検証結果の読み取りを誤らないためのものです。
本検証が再現している実務シナリオ
本検証は、実務において想定される、次のような場面を再現することを目的としています。
担当者が、業務ツールや社内AIのUIに入力した内容を、外部のLLMに送信しようとした瞬間に、その入力内容と送信先が、組織およびプロジェクトで定義されたAIポリシーに照らして許容されるかどうかを事前に判定する。
本検証で用いた構成は、この「外部LLMに送信する直前」の判定処理を擬似したものです。
重要なのは、本検証が
- 入力内容をLLMに渡した後で検知する
- AIの内部挙動を制御する
のではなく、
AIを呼び出す入口で制御する(=生成処理を開始する前段での制御)
という設計思想に基づいている点です。
以降の検証①〜③では、この前提のもとで、ポリシー定義や制御レベルを変更した場合にどのような挙動が観測されたのかを、事実として整理していきます。
※本検証では、PII判定の精度や検知手法そのものは評価対象としていません。
PII判定は独立した技術領域であり、その精度・限界・リスク許容は、システム要件および運用設計の中で別途判断されるべきものと位置づけています。
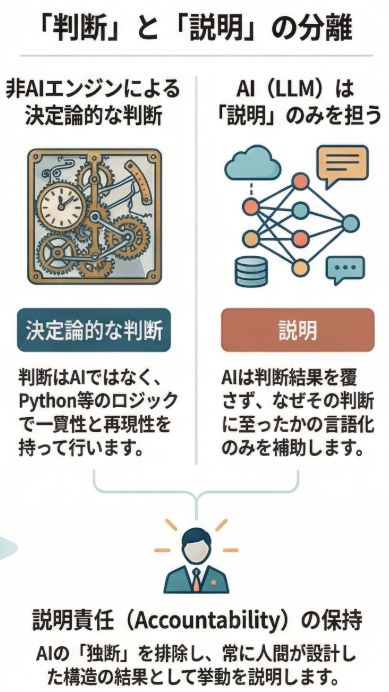
思想の整理|AIに「判断」を任せないという前提
本記事全体を貫く最も重要な前提は、次の一点です。
AIに判断を任せない
判断と責任の主体は、常に人(プロジェクトマネージャ)である
ここで言う「判断」とは、
- 利用してよいか/いけないか
- 例外を認めるかどうか
- 組織として許容できるかどうか
といった、説明責任を伴う意思決定を指します。
AI(LLM)は、その判断を支援する存在ではありますが、判断そのものや責任を引き受ける存在ではありません。
そのため本検証では、次の点は評価対象にしていません。
- AIが正しい判断をしたか
- AIが賢く振る舞ったか
代わりに、本検証が見ているのは次の点です。
- 人が設計したAIポリシー構造に基づいて
- AIの挙動がどのように制御され
- その判断結果を人が説明できる状態になっているか
この立場に立つことで、「AIが勝手に判断した」という状況を意図的に排除しています。
用語の定義 本記事におけるAIポリシーの意味
本記事における「AIポリシー」という言葉は、単なるルール文書や宣言文を指すものではありません。
前回の記事では「AI憲章」という言葉を用いましたが、本記事では次のように定義します。
AIポリシー
AIの利用可否や振る舞いを、人が説明可能な形で制御するための判断構造
このAIポリシーを、責務の異なる三つのレイヤーに分けて扱います。
組織AIポリシー
- 組織として絶対に守るべき原則を定義する
- 法令・コンプライアンス・個人情報保護などが該当
- プロジェクト単位では変更できない
プロジェクトAIポリシー
- 組織AIポリシーに準拠したうえで
- プロジェクト固有の条件や裁量を定義する
- PM承認を前提とした例外条件などを含む
実装AIポリシー
- 上記二つのポリシー定義を入力として評価され
- 実際のAIの挙動として現れる結果全体を指す概念
重要なのは、実装AIポリシーが一枚の設定ファイルを意味しないという点です。
複数のポリシー定義と、それを解釈・評価するロジックの組み合わせによって、初めて「実装AIポリシーとしての振る舞い」が現れます。
検証の前提共有 本検証で何を前提とし、何を前提としないか
本検証には、あらかじめ明示しておくべき前提条件があります。
まず、本検証は特定のLLMの性能や正しさを評価するものではありません。
LLMは本検証において、
- ポリシー間の関係性を言語的に解釈し
- 判断結果を人に説明する役割
としてのみ用いています。
そのため、
- 使用するLLMが異なれば
説明の仕方や表現、強調点が変わる可能性があります
これは本検証において「問題」ではありません。
むしろ本検証の目的は、
LLMという解釈主体が変わり得る前提のもとでも、
人が説明責任を果たせる構造になっているか
を確認することにあります。
また、本検証では次の構成を前提としています。
- 組織AIポリシーとプロジェクトAIポリシーを
別ファイル・別管理とする - 両者の対応関係に基づいて
実装AIポリシーを評価する - 判断結果とAIの挙動を
ログとして可視化する
この構成により、
- AIの挙動を「AIの判断」としてではなく
- 人が設計したポリシー構造の結果として
説明できる状態を作っています。
以降の章では、この前提を置いたうえで、ポリシー条件を変更した場合に、実際に何が起きたのかを評価や解釈を加えず、事実ベースで整理していきます。
が起きたのかを、検証結果として整理していきます。
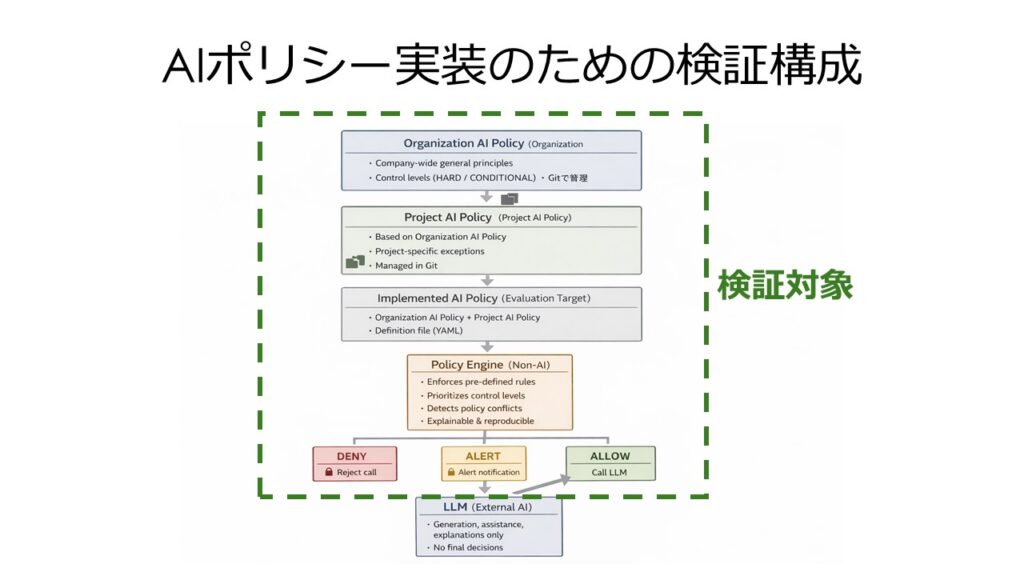
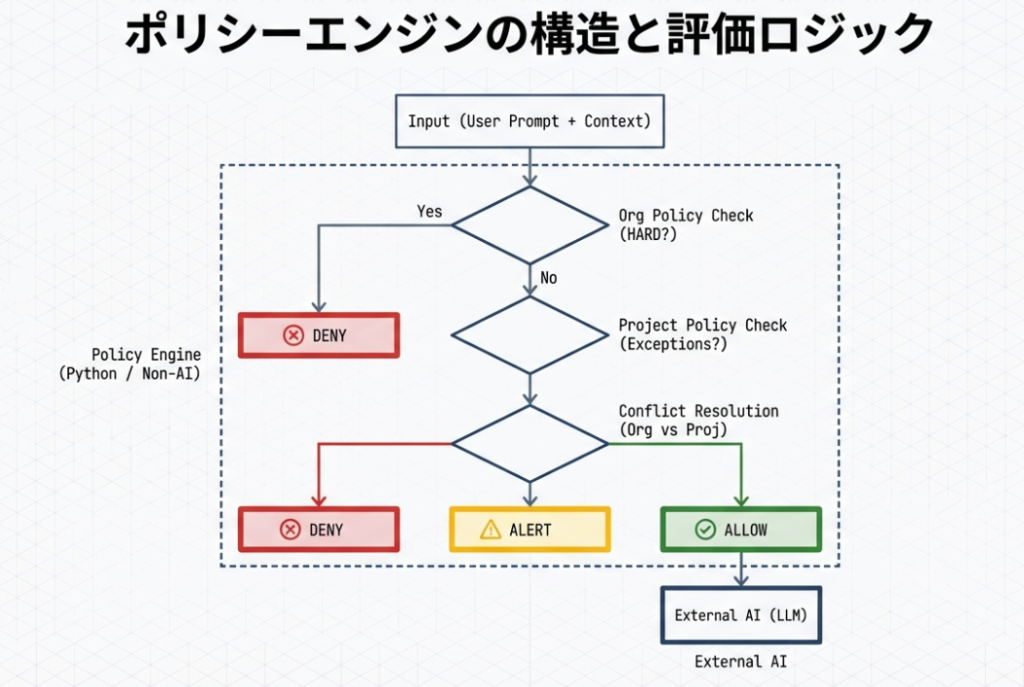
ポリシーエンジンの構造と評価ロジック
ここまでで、組織AIポリシーとプロジェクトAIポリシーがYAMLファイルとして分離管理されていることを確認しました。
本章では、それらをどのように評価し、最終的な挙動に変換しているのか、すなわち「ポリシーエンジン」の構造と論理を整理します。
ポリシーエンジンとは何か
本検証におけるポリシーエンジンとは、
- 組織AIポリシー定義ファイル
- プロジェクトAIポリシー定義ファイル
- 実行時の入力条件(PII有無、宛先、PM承認など)
を入力として受け取り、
LLMを呼び出してよいかどうかを、人が説明可能な形で判定する仕組み
を指します。
重要なのは、このポリシーエンジン自体はAIではないという点です。
本検証では、Pythonによる決定論的なロジックとして実装しています。
なぜポリシーエンジンをAIに任せていないのか
この点は、本記事の思想と直結します。
AIポリシーの役割は、
「AIをどう使うか」を決めることであって、
「AIに決めさせること」ではありません。
そのため、
- 判定条件が追跡できない
- 同じ入力でも結果が揺らぐ
- なぜその判断に至ったのか説明できない
といった特性を持つAIを、ポリシー評価の中核に置くことは意図的に避けています。
ポリシーエンジンは、
- 同じ条件なら必ず同じ結果になる
- 判断根拠をログとして残せる
- 後から第三者が検証できる
という性質を持つ必要があります。
この要件を満たすため、本検証では非AIのロジック(Python)を採用しています。
なお、実運用においては、AIポリシーそのものはYAMLファイルとして定義し、Git上で管理・レビュー・承認することも可能です。
ポリシーエンジンの評価フロー(概要)
ポリシーエンジンは、概ね次の順序で評価を行います。
- 入力条件の正規化
- PIIを含むか
- 宛先は外部LLMか
- PM承認の有無 など
- 組織AIポリシーの評価
- 制御レベルが HARD のポリシーを最優先で評価
- 条件に一致した場合、その時点で判断を確定
- プロジェクトAIポリシーの評価
- 組織AIポリシーによりブロックされていない場合のみ評価
- 条件付き例外(ALLOW)を判定
- 制御レベルの衝突検知
- 組織:DENY(HARD)
- プロジェクト:ALLOW(CONDITIONAL)
といった矛盾が存在する場合は、
制御レベルの優先順位に基づいて決着
- 最終判定の生成
- allow_call_llm(True / False)
- blocked_by(どのポリシーが効いたか)
- alerts(通知対象)
- reason / debug(説明用情報)
この結果をもとに、LLMを呼び出すかどうかが決定されます。
※4. 制御レベルの衝突検知は組織AIポリシーによって即時終了しない実装、もしくは判断確定後も評価を継続する実装(検証③)において有効となるようにしています。
※後述の検証①では、下図のとおりHARD違反時に評価を即時終了する実装としました。
検証③では、この基本構造を維持したまま、判断確定後も評価を継続し、説明生成のための衝突情報を取得する実装に変更しています。
ポリシーが増えてもエンジンを書き換えないための設計
ポリシーが増えるたびにエンジンを書き換えるなら実用的ではないのではないか?
という懸念も無視できません。
本検証のポリシーエンジンは、
- ポリシーの数には依存しない
- 評価するのは
- 制御レベル
- 効果(ALLOW / DENY / ALERT)
- 条件の一致
という共通構造のみ
という前提で設計しています。
新しいポリシーを追加する場合も、
- YAMLに定義を追加する
- 既存の制御レベル・効果・条件を使う
だけで済み、エンジン側のロジックは原則として変更不要です。
この点が、
- ポリシーをGitで管理できる
- レビューや承認プロセスに載せられる
- 運用フェーズで破綻しにくい
理由になっています。
LLMはどこで使われているのか
本検証において、LLMは
- ポリシー評価の結果を受け取った後
- 「なぜこの判断になったのか」を
- 人に説明するため
にのみ使用しています。
つまり、
- 判定 → ポリシーエンジン(非AI)
- 説明 → LLM(AI)
という明確な役割分担をしています。
この分離によって、
- AIが判断をすり替える
- 説明と実態が食い違う
といった問題を避けています。
この構造が意味するもの
このポリシーエンジン構造によって、
- AIの挙動は
「AIが決めた結果」ではなく「人が設計したポリシー構造の結果」として説明できます - LLMが異なっても、判断結果そのものは変わりません
- 変わるのは説明の仕方だけです
次章以降では、このポリシーエンジン構造を前提として、
- 制御レベルが HARD の場合
- CONDITIONAL に下げた場合
- その結果、何が変わり、何が変わらなかったのか
を、評価や解釈を加えずに事実として整理していきます。
検証に用いたAIポリシーと対応表
本章では、今回の検証で実際に使用したAIポリシーを明示し、三層のAIポリシーがどのように対応付けられているかを整理します。
この章の目的は二つあります。
- 読者が「何を前提に検証が行われたのか」を正確に把握できるようにすること
- 検証結果を読み解く際の人間側の拠り所を用意すること
以降の検証結果は、すべて本章で示すポリシー定義と対応関係を前提として説明します。
検証における基本方針
今回の検証では、AIポリシーを次の方針で設計・管理しています。
- 組織AIポリシーとプロジェクトAIポリシーは別ファイル・別管理
- プロジェクト側は、組織AIポリシーを直接変更できない
- 実装AIポリシーは単一ファイルではなく、
複数のポリシー定義と評価ロジックの結果として現れる挙動とする
この構成により、
- 「どの判断がどのポリシーに基づくものか」
- 「なぜこの挙動になったのか」
を後から説明可能な状態にしています。
組織AIポリシー(定義内容)
組織AIポリシーは、組織として越えてはいけない原則を定義するレイヤーです。
今回の検証では、以下の二つを最小構成として設定しました。
GOV-01(組織・主)
- 内容
個人情報(PII)を外部LLMに送信しない - 目的
個人情報保護およびコンプライアンスの担保 - 制御レベル
条件付き(CONDITIONAL)
※ 条件に合致した場合に制御が発動する - 効果
DENY(処理のブロック) - 管理主体
組織
SEC-02(組織・従)
- 内容
ポリシー違反または疑義が生じた場合、セキュリティ委員会へ通知する - 目的
事後監査およびインシデント対応 - 制御レベル
条件付き(CONDITIONAL) - 効果
ALERT(通知) - 管理主体
組織
これらは、プロジェクト単位では変更できない前提で扱われます。
※なお、前回の記事で整理したAI憲章においては、GOV-01 は「HARD(常時強制)」として位置づけていました。(本来はそうするべき内容のポリシーです。)
本検証では、ポリシー間の衝突時の挙動と説明可能性を観測するため、制御レベルを一段階下げ、CONDITIONAL として実装しています。
これは運用上の推奨を示すものではなく、あくまで検証のための意図的な設定です。
プロジェクトAIポリシー(定義内容)
プロジェクトAIポリシーは、組織AIポリシーに準拠したうえで、プロジェクト固有の裁量を定義するレイヤーです。
今回の検証では、以下のポリシーを設定しました。
PROJ-EX-01(プロジェクト)
- 内容
個人情報を含む場合でも、プロジェクトマネージャが承認した場合に限り外部LLMの利用を許可する - 目的
実務上避けられないケースへの対応 - 制御レベル
ALLOW(条件付き許可) - 管理主体
プロジェクト
重要なのは、このポリシーが組織AIポリシーを上書きするものではないという点です。
あくまで、組織AIポリシーとの関係性の中で評価されます。
三層AIポリシーの対応表
以上を踏まえ、本検証で用いたAIポリシーの対応関係を整理すると、次のようになります。
AIポリシー対応表
| レイヤー | ポリシーID | 内容要約 | 実装AIポリシー 定義ファイル | 制御レベル | 効果 |
|---|---|---|---|---|---|
| 組織 | GOV-01 | PIIを外部LLMに送信しない | org.yaml | CONDITIONAL | DENY |
| 組織 | SEC-02 | 違反・疑義時に通知 | org.yaml | CONDITIONAL | ALERT |
| プロジェクト | PROJ-EX-01 | PIIの外部LLMへの送信は、PM承認時のみ例外許可 | project.yaml | ALLOW | ALLOW |
この表は、
- 「何が定義されているか」を示すものであり
- 「どう評価されたか」は含んでいません
評価結果については、次章で事実として整理します。
この対応表が果たす役割
この対応表は、単なる一覧ではありません。
- 人が判断結果を確認する際の基準点であり
- LLMの挙動を評価する際の比較軸であり
- 「なぜこの判断になったのか」を説明するための根拠
です。
以降の検証結果では、
- この対応表のどのポリシーが評価され
- どの制御レベルが発動し
- どのような挙動として現れたのか
を一つずつ確認していきます。
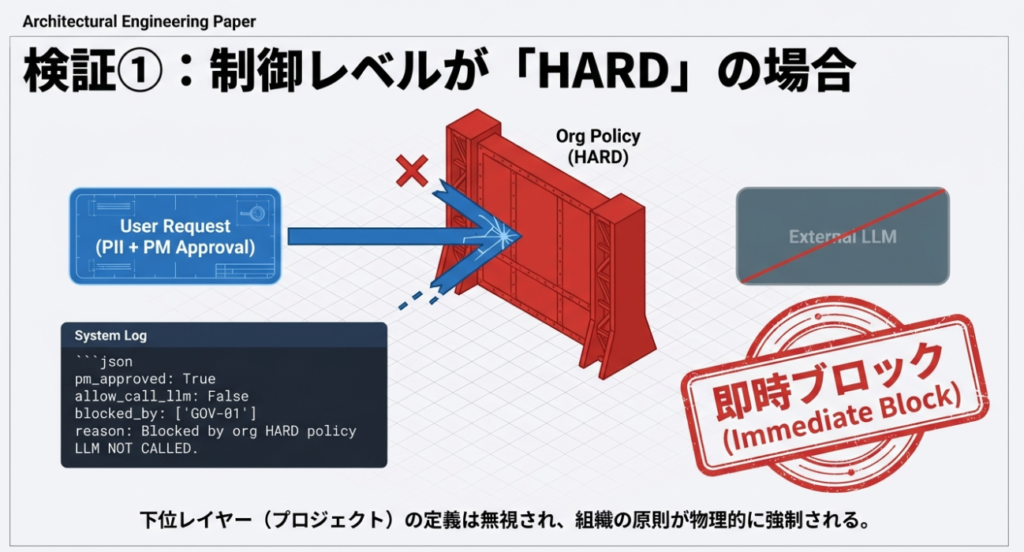
検証①:制御レベルがHARDの場合
組織AIポリシーが最優先される状態
本検証では、組織AIポリシーの制御レベルを HARD(常時強制)とした場合に、
AIの挙動がどのようになるかを確認した。
この検証は、
「組織として越えてはいけない原則が、実装上どのように反映されるか」
を事実として把握することを目的としている。
検証条件
- 組織AIポリシー
- GOV-01
- 内容:個人情報(PII)を外部LLMに送信しない
- 制御レベル:HARD(Always On)
- 効果:DENY
- SEC-02
- 制御レベル:有効(通知設定あり)
- GOV-01
組織AIポリシー定義ファイル(org.yaml)
org_policies:
- id: GOV-01
title: "No PII to External LLM"
description: >
Personal Identifiable Information (PII) must not be sent
to any external Large Language Model.
control_level: HARD # Always On
effect: DENY
scope:
destination: external_llm
condition:
contains_pii: true
- id: SEC-02
title: "Alert Security Committee on Violation or Suspicion"
description: >
Notify the security committee when an AI policy violation
or suspicious behavior is detected.
control_level: CONDITIONAL
effect: ALERT
condition:
on_violation: true
- プロジェクトAIポリシー
- PROJ-EX-01
- 内容:PIIの外部LLMへの送信は、PM承認時のみ例外許可
- 定義あり(ただし組織AIポリシーが優先される)
- PROJ-EX-01
プロジェクトAIポリシー定義ファイル(project.yaml)
project_policies:
- id: PROJ-EX-01
title: "Conditional Exception for PII with PM Approval"
description: >
Sending PII to an external LLM is allowed
only when explicitly approved by the Project Manager.
effect: ALLOW
condition:
contains_pii: true
destination: external_llm
pm_approved: true
- 入力データ
- PIIを含むテキスト
- 宛先
- 外部LLM
- PM承認
- 有無にかかわらず検証
実行ログ
- 入力テキストに PII が含まれていることを検知
- 宛先が外部LLMであることを確認
- 組織AIポリシー(GOV-01)が評価対象として最初に適用される
- 制御レベル HARD により、他レイヤーの評価よりも優先して DENY が確定
- プロジェクトAIポリシー(PROJ-EX-01)は最終判断には反映されない
- LLM 呼び出しは実行されない
- SEC-02 に基づく通知処理が発生
==== 違反系(PIIあり・未承認) ====
pm_approved: False
allow_call_llm: False
blocked_by: ['GOV-01']
alerts: ['SEC-02']
reason: Blocked by org HARD policy: ['GOV-01']
debug: {'contains_pii': True, 'pm_approved': False, 'destination': 'external_llm'}
LLM NOT CALLED.
==== 矛盾検証(PIIあり・PM承認あり) ====
pm_approved: True
allow_call_llm: False
blocked_by: ['GOV-01']
alerts: ['SEC-02']
reason: CONTROL-LEVEL CONFLICT: Org HARD DENY(['GOV-01']) overrides Project ALLOW(['PROJ-EX-01']). Blocking.
debug: {'contains_pii': True, 'pm_approved': True, 'destination': 'external_llm', 'project_allows': ['PROJ-EX-01']}
LLM NOT CALLED.
- PIIが含まれる場合、PM承認の有無にかかわらず
allow_call_llm: Falseとなった blocked_by: ['GOV-01']が常に付与されたalerts: ['SEC-02']が付与された- PM承認ありのケースでは、
project_allows: ['PROJ-EX-01']が記録されたが、最終判断はブロックだった - 両ケースとも
LLM NOT CALLED.となった
観測された挙動
- PIIを含む入力は、すべて外部LLMへの送信前にブロックされた
- PM承認の有無は、判定結果に影響しなかった
- プロジェクトAIポリシーによる例外条件は参照されなかった
- LLMからの応答は発生しなかった
- 組織AIポリシーが最優先で適用された
Input
↓
[ Organization AI Policy ]
└─ HARD rules (always on)
└─ violation? → 即 DENY
↓
[ Project AI Policy ]
└─ CONDITIONAL / exception rules
↓
ALLOW / DENY
起きた事実の整理
- 制御レベルが HARD の場合、組織AIポリシーは常に最優先で適用された
- 下位レイヤー(プロジェクトAIポリシー)の定義が存在していても、評価対象にはならなかった
- AIの挙動は、「組織ポリシーによる即時ブロック」として一貫していた
- 判断結果は、AIやLLMの裁量ではなく、事前に定義されたポリシー構造によって決定された
※ 本章では、
この挙動が妥当かどうか、実運用として適切かどうかについては扱わない。
評価・考察は、後続の章でまとめて行う。
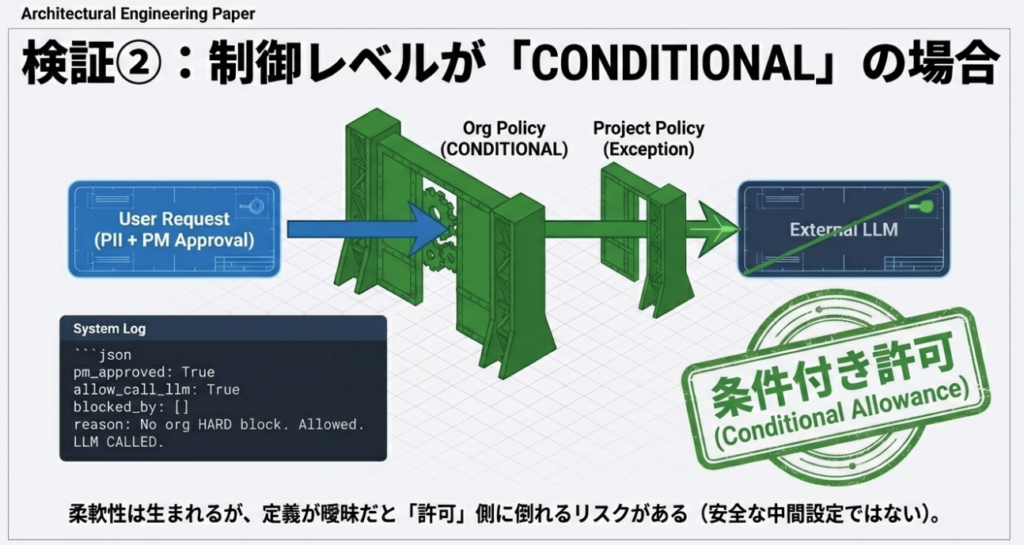
検証②:制御レベルが CONDITIONAL の場合
組織AIポリシーとプロジェクトAIポリシーが条件付きで調整される状態
本検証では、組織AIポリシーの制御レベルを CONDITIONAL(条件付き) とした場合に、
AIの挙動およびポリシー評価の流れがどのように変化するかを確認しました。
本章の目的は、組織ポリシーが絶対優先ではない場合に、下位レイヤー(プロジェクトAIポリシー)がどのように関与するかを、事実として整理することです。
検証条件
組織AIポリシー
GOV-01
- 内容:個人情報(PII)を外部LLMに送信しない
- 制御レベル:CONDITIONAL
- 効果:DENY
- 管理主体:組織
SEC-02
- 内容:違反または疑義発生時に通知
- 制御レベル:CONDITIONAL
- 効果:ALERT
組織AIポリシー定義ファイル(org.yaml)
org_policies:
- id: GOV-01
title: "No PII to External LLM"
description: >
Personal Identifiable Information (PII) must not be sent
to any external Large Language Model.
control_level: CONDITIONAL
effect: DENY
scope:
destination: external_llm
condition:
contains_pii: true
- id: SEC-02
title: "Alert Security Committee on Violation or Suspicion"
control_level: CONDITIONAL
effect: ALERT
condition:
on_violation: true
プロジェクトAIポリシー
PROJ-EX-01
- 内容:PIIの外部LLMへの送信は、PM承認時のみ例外許可
- 管理主体:プロジェクト
プロジェクトAIポリシー定義ファイル(project.yaml)
project_policies:
- id: PROJ-EX-01
title: "Conditional Exception for PII with PM Approval"
description: >
Sending PII to an external LLM is allowed
only when explicitly approved by the Project Manager.
effect: ALLOW
condition:
contains_pii: true
destination: external_llm
pm_approved: true
入力データ
- PII を含むテキスト
宛先
- 外部LLM
PM承認
- 未承認ケース
- 承認済みケース
の両方を検証
実行ログ(要点)
違反系(PIIあり・未承認)
pm_approved: False
allow_call_llm: True
blocked_by: []
alerts: []
reason: No org HARD block. Allowed to call LLM.
debug: {'contains_pii': True, 'pm_approved': False, 'destination': 'external_llm'}
LLM CALLED.
予盾検証(PIIあり・PM承認あり)
pm_approved: True
allow_call_llm: True
blocked_by: []
alerts: []
reason: No org HARD block. Allowed to call LLM.
debug: {'contains_pii': True, 'pm_approved': True, 'destination': 'external_llm', 'project_allows': ['PROJ-EX-01']}
LLM CALLED.
観測された挙動
- PIIを含む入力であっても、組織AIポリシーによる即時ブロックは発生しなかった
- 組織AIポリシーは「HARD制御」としては機能せず、評価結果は条件付きとなった
- プロジェクトAIポリシー(PROJ-EX-01)が評価対象として参照された
- PM承認の有無が、最終判断に影響した
- 両ケースとも LLM CALLED. となった
起きた事実の整理
- 制御レベルが CONDITIONAL の場合、組織AIポリシーは絶対優先ではなかった
- 組織AIポリシーとプロジェクトAIポリシーの両方が評価対象となった
- PM承認というプロジェクト側の条件が、最終判断に影響した
- AIの挙動は、ポリシー定義と承認状態に基づいて一貫していた
- 判断結果は、LLMの裁量ではなく、事前定義されたポリシー構造と入力条件によって決定された
※ 本章では、
この挙動が適切かどうか、組織ガバナンスとして望ましいかについては評価しない。
考察および比較は、後続の章でまとめて行う。
検証③:制御レベル衝突時に LLM で説明を生成する場合
ポリシー衝突の検知と説明を AI に補助させた状態
本検証では、組織AIポリシーとプロジェクトAIポリシーの判断が衝突した場合において、
- 最終判断は従来どおりポリシーエンジンで確定させたまま
- その判断理由の説明のみを LLM に生成させた場合
に、どのような挙動が観測されるかを確認しました。
本検証では、組織AIポリシーおよびプロジェクトAIポリシーの評価自体は従来どおりポリシーエンジンで完結させています。
LLMには、最終判断結果(DENY)および、その判断に至る過程で検出されたポリシー衝突情報のみを入力し、判断理由の説明文生成を補助させました。そのため、LLMはALLOW/DENYの判断には一切関与していません。
本章の目的は、
AIに判断を委ねることなく、判断理由の説明のみを補助させた場合に何が起きるか
を、事実として整理することです。
検証条件
組織AIポリシー
GOV-01
- 内容:個人情報(PII)を外部LLMに送信しない
- 制御レベル:HARD(※)
- 効果:DENY
※ 本検証では、判断ゲートとしては常時適用しているが、
LLMには判断確定後の説明対象としてのみ渡している
SEC-02
- 内容:違反または疑義発生時に通知
- 制御レベル:CONDITIONAL
- 効果:ALERT
※ 組織AIポリシーの構成は、検証①と同一とする。
プロジェクトAIポリシー
PROJ-EX-01
- 内容:PIIの外部LLMへの送信は、PM承認時のみ例外許可
- 効果:ALLOW
実装条件(検証③の追加条件)
- 判断結果(ALLOW / DENY)は、従来どおり ポリシーエンジンで確定する
- LLM は、判断確定後の説明生成のみに使用する
- LLM は、判断結果を変更する権限を持たない
なお、本検証③では、検証①とは異なり、ポリシー定義は共通としたまま、ポリシーエンジンの評価ロジックを変更しています。判断結果は従来どおり確定するが、説明生成のために衝突情報を取得できる実装としました。
入力データ
- PII を含むテキスト
宛先
- 外部 LLM
PM承認
- 承認あり(ポリシー衝突が発生する条件)
実行ログ(要点)
pm_approved: True
allow_call_llm: False
blocked_by: ['GOV-01']
alerts: ['SEC-02']
reason: CONTROL-LEVEL CONFLICT:
Org HARD DENY(['GOV-01']) overrides
Project ALLOW(['PROJ-EX-01']). Blocking.
debug: {
'contains_pii': True,
'pm_approved': True,
'destination': 'external_llm',
'project_allows': ['PROJ-EX-01']
}
LLM CALLED FOR EXPLANATION ONLY.
LLM が生成した説明(抜粋)
組織AIポリシー GOV-01 は、個人情報(PII)を外部LLMに送信することを
常に禁止する最上位の制御として定義されています。
プロジェクトAIポリシー PROJ-EX-01 では、PM承認を条件とした例外が
定義されていますが、この例外は組織AIポリシーを上書きするものではありません。
そのため、両ポリシーの判断が衝突した場合は、
制御レベルに基づき組織AIポリシーが優先され、
外部LLMへの送信は実行されませんでした。
※ 上記の説明文は、既に確定した判断結果を変更するものではなく、判断理由を言語化したものである。
観測された挙動
- 組織AIポリシーとプロジェクトAIポリシーの衝突が検知された
- 最終判断は、従来どおり DENY のまま変更されなかった
- LLM は、判断確定後にのみ呼び出された
- LLM の出力には、以下の要素が含まれていた
- 適用されたポリシー
- 優先順位
- 衝突理由
- LLM が判断主体として振る舞う挙動は観測されなかった
Input
↓
[ 組織AIポリシー ]
+
[ プロジェクトAIポリシー ]
↓
統合評価ロジック
↓
コンフリクト検出
起きた事実の整理
- ポリシー衝突は、構造的に検知された
- 最終判断は、制御レベルに基づき確定した
- LLM は、判断結果を覆すことはなかった
- LLM は、人が理解するための説明生成にのみ利用された
- 判断と説明が、明確に分離された状態で動作した
※ 本章では、この仕組みが実運用に適しているか、説明生成をAIに委ねることの是非については評価しない。考察および全体比較は、後続の章でまとめて行う。
検証結果の整理|三つの検証から確認できた事実
本章では、検証①〜③で観測された事実を横断的に整理します。
ここでは結論や是非の判断は行わず、実装および実行ログから確認できた事実のみを記載します。
制御レベル HARD の組織AIポリシーは、常に最優先で適用される(検証①)
検証①では、組織AIポリシー(GOV-01)を制御レベル HARD として設定しました。
この条件下では、
- 入力に PII が含まれている場合
- PM承認の有無にかかわらず
- プロジェクトAIポリシーに例外許可が定義されている場合であっても
次の挙動が一貫して観測されました。
- 組織AIポリシーが最初に評価されました
- DENY が即時に確定しました
- プロジェクトAIポリシーは評価対象になりませんでした
- 外部LLMの呼び出しは行われませんでした
- 通知ポリシー(SEC-02)が発動しました
制御レベル HARD を持つ組織AIポリシーは、下位レイヤーの定義を参照せず、常に最優先で挙動を決定しました。
制御レベル CONDITIONAL の組織AIポリシーは、即時ブロックにはならない(検証②)
検証②では、組織AIポリシー(GOV-01)を制御レベル CONDITIONAL として設定しました。
この条件下では、
- PII を含む入力であっても
- 組織AIポリシーによる即時ブロックは発生せず
- プロジェクトAIポリシーが評価対象として参照されました
その結果、以下の事実が観測されました。
- 組織AIポリシーとプロジェクトAIポリシーの両方が評価されました
- PM承認の有無が最終判断に影響しました
- PM承認がない場合でも、LLMが呼び出されるケースが存在しました
- 両ケースとも LLM CALLED. となりました
この挙動は実装ミスやLLMの誤動作ではなく、
制御レベル CONDITIONAL の組織AIポリシーが即時DENYとして機能しなかった結果として観測されたものです。
ポリシー衝突時でも、判断結果はAIではなくポリシーエンジンで確定する(検証③)
検証③では、組織AIポリシー(HARD)とプロジェクトAIポリシー(ALLOW)が衝突する条件を設定し、LLMを「説明生成のみに使用」しました。
この条件下では、次の事実が確認されました。
- ポリシー衝突は、ポリシーエンジンによって構造的に検知されました
- 制御レベルに基づき、最終判断は DENY に確定しました
- LLMは、判断確定後にのみ呼び出されました
- LLMは判断結果を変更しませんでした
- LLMの出力は、
- 適用されたポリシー
- 優先順位
- 衝突理由
を説明する内容で構成されていました
判断と説明は、実装上および挙動上ともに分離されていました。
三つの検証を通じて一貫して確認できた事実
検証①〜③を通じて、次の点が一貫して観測されました。
- AI(LLM)は、最終判断の主体にはなっていませんでした
- 判断結果は、事前に定義されたポリシー構造と制御レベルによって決定されていました
- LLMの役割は、
- 呼び出されない
- 呼び出される
- 説明生成にのみ使用される
という形で、ポリシー評価の結果に従って制御されていました
- AIの挙動は、入力条件とポリシー定義に対して一貫していました
これらの事実は、AIの性能や賢さによるものではなく、人が設計したポリシー構造と評価ロジックの結果として現れた挙動です。
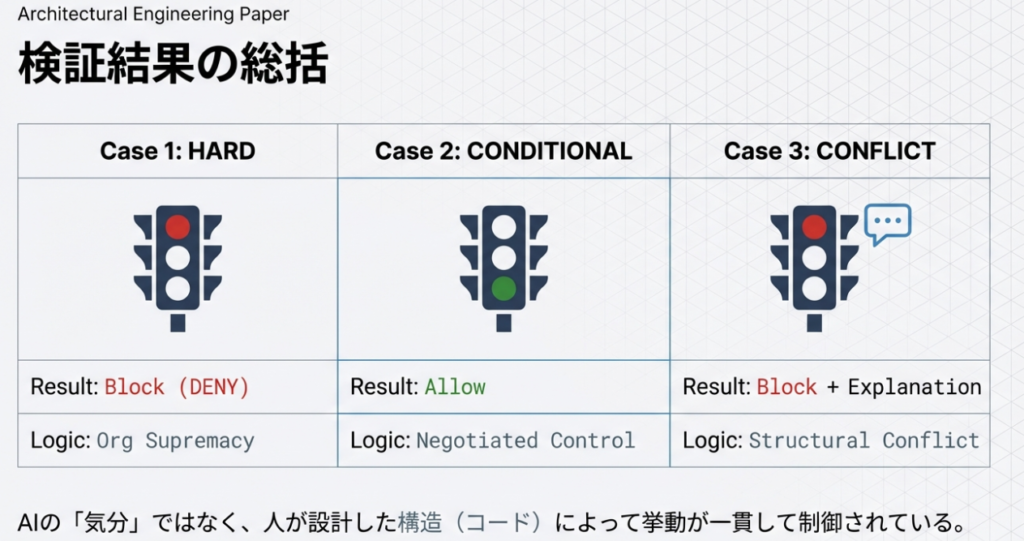
※ Case 3 においても、最終判断(Block / Allow)は事前に定義されたポリシー評価ロジックによって確定しており、AI(LLM)は判断理由の説明生成のみに使用されている。
まとめ 今回の検証で得られた収穫と今後の展望
本記事では、PMBOK第8版で示唆されている「AIポリシー」という考え方を起点に、
組織AIポリシー・プロジェクトAIポリシー・実装AIポリシーという三層構造を前提として、
実際にポリシーを実装した場合にAIの挙動がどのようになるのかを検証しました。
本章では、検証①〜③の事実整理を踏まえ、今回の検証から得られた収穫と、今後検討すべき論点について整理します。
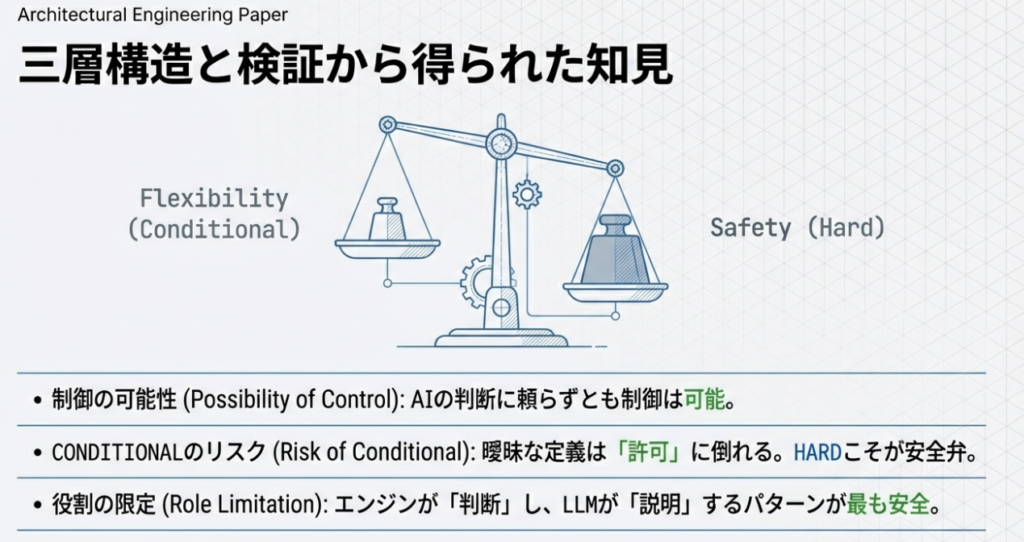
今回の検証で得られた主な収穫
AIにポリシー運用を任せずとも、管理・制御は可能であることが確認できました
今回の検証では、
AI(LLM)にポリシー判断そのものを委ねることはせず、
人が定義したポリシー構造と制御レベルに基づいて挙動を決定する構成を取りました。
その結果、
- 判断主体は常にポリシーエンジンにあり
- LLMは、
- 呼び出されない
- 呼び出される
- 説明生成のみに利用される
という形で制御され
- AIが独自判断でポリシーを逸脱する挙動は観測されませんでした
このことから、AIにポリシー運用を任せなくても、AI利用を管理・統制する構造は成立し得る
という点が、事実として確認できました。
一方で、これはあくまで最小構成での検証結果であり、実運用に適用するには、さらなる検討が必要であることも同時に示されています。
CONDITIONAL ポリシーは、条件定義を誤ると「許可に倒れる」ことが明確になりました
今回の検証における大きな学びの一つが、制御レベル CONDITIONAL の扱いです。
検証②では、
- 組織AIポリシーを CONDITIONAL とした場合
- 条件が明示されていない範囲については
- 即時DENYが発動せず
- プロジェクトAIポリシーの評価結果がそのまま挙動に反映される
という事実が確認されました。
これは、実装ミスやAIの誤動作ではなく、ポリシー定義そのものが許容する構造になっていた結果です。
この検証から、
- CONDITIONAL は「安全な中間設定」ではないこと
- 条件を明示しなければ、制御は成立しないこと
- 曖昧なポリシーは、実装段階で曖昧な挙動として現れること
が、実行ログを通じて明確になりました。
判断と説明を分離することで、AIの役割を限定できる可能性が見えました
検証③では、ポリシー衝突時において、
- 判断は従来どおりポリシーエンジンで確定し
- LLMは、その判断結果の説明生成のみに利用する
という構成を取りました。
この構成では、
- 判断結果がAIによって覆されることはなく
- LLMは「なぜその判断になったのか」を人に説明する役割に限定され
- 判断と説明が明確に分離された挙動が確認できました
これは、
AIを「判断主体」にしないまま、人間の理解を補助する存在として活用できる可能性を示唆する結果と言えます。
今後の展望と検討が必要な点
今回の検証は、AIポリシー実装の可能性を示す一方で、今後検討すべき課題も明確にしました。
文脈(コンテキスト)の欠如
本検証では、
人が入力した内容を外部LLMに送信してよいかという制御を中心に扱いました。
これによって、「入力テキストに禁止ワードが含まれているか」という観点での判定が可能になりました。
しかしながら、業務においてはセキュリティ担当者がハッカーの手口などを検索する必要性も出てきます。そこには、禁止ワードを入力する必要性も出てきます。
このように、ポリシーを実運用に適合させるためには、実務に合わせた実装が必要になります。必要に応じて、動的に禁止、承認を使い分けなければならない仕組みが必要になると考えています。
倫理的判断の限界
倫理的な側面は定量的なリスクスコアだけでは測れない可能性も考えられます。
例えば、キーワード、文脈も正しいかもしれないが、自社のイメージを損なうような表現がある場合など、禁止事項ではないが、企業のポリシーとして許可すべきでない場合もあります。
このようなリスクをどのように評価して、アクションを取るかが課題として残されています。
ログ化と分析の監査
多くのシステムでは「ブロック」しておわりという状況だと思います。遮断されたログの活用を行い、「なぜブロックされたのか」「現場の担当者は何をしようとしていたか」などをポリシーと照らし合わせ、ポリシーにフィードバックする取り組みをすることで、安定、高速、高性能化したAIポリシーの仕組みが完成されると考えます。
おわりに
本記事で行った検証は、「これが正解である」という結論を示すものではありません。
むしろ、
- AIポリシーをどのような構造で考えるべきか
- どこまでをAIに任せ、どこを人が担うべきか
- 曖昧な設計がどのような挙動を生むのか
を、実装とログを通じて可視化することに主眼を置いています。
AI技術は今後も進化し続けますが、説明責任を人が負うという前提そのものは、容易に変わらないと考えています。
本記事が、AIポリシーを「理念」ではなく「設計対象」として考えるきっかけとなり、さらなる議論や検証につながれば幸いです。

参考文献
※本章にはPRを含みます。
- PMBOK®ガイド第8版
Project Management Institute(PMI)


コメント