序文
「あの件、進捗どうですか?」と聞かれて、「今、開発が確認中です」としか答えられない。 PMが即答できない理由は、能力不足ではなく、管理しているデータベース(DB)の解像度が低いからです。
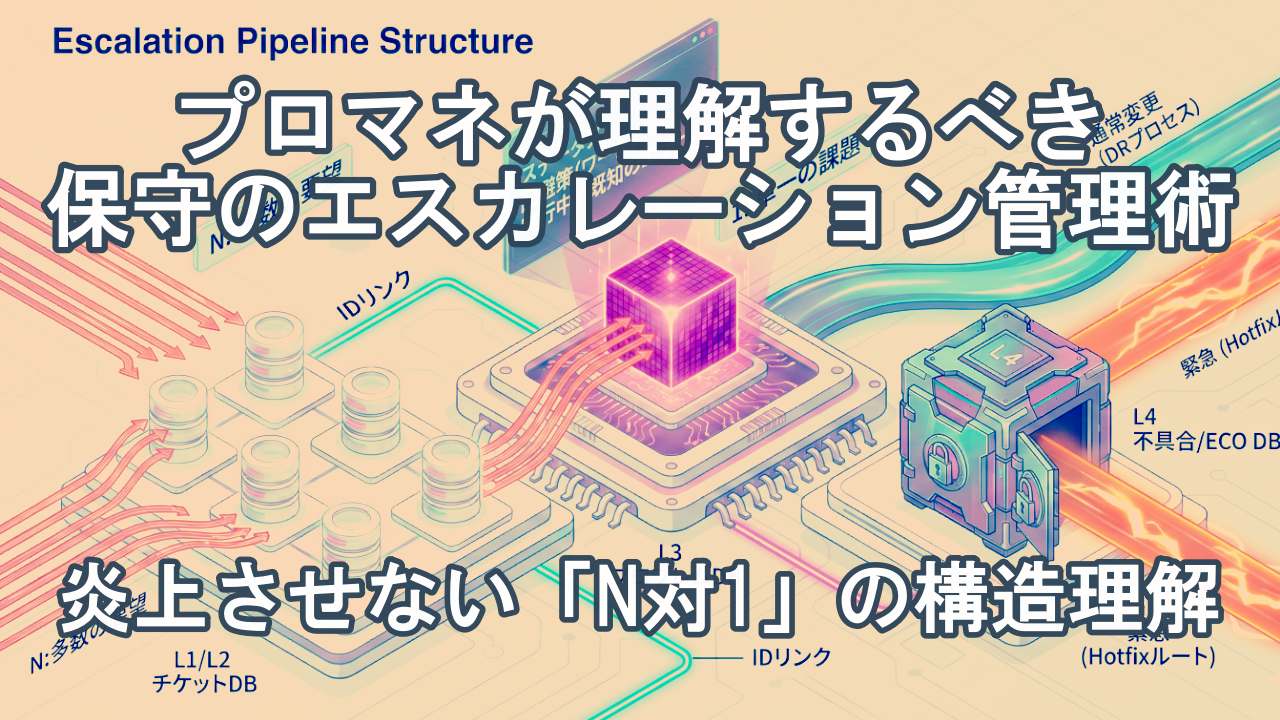
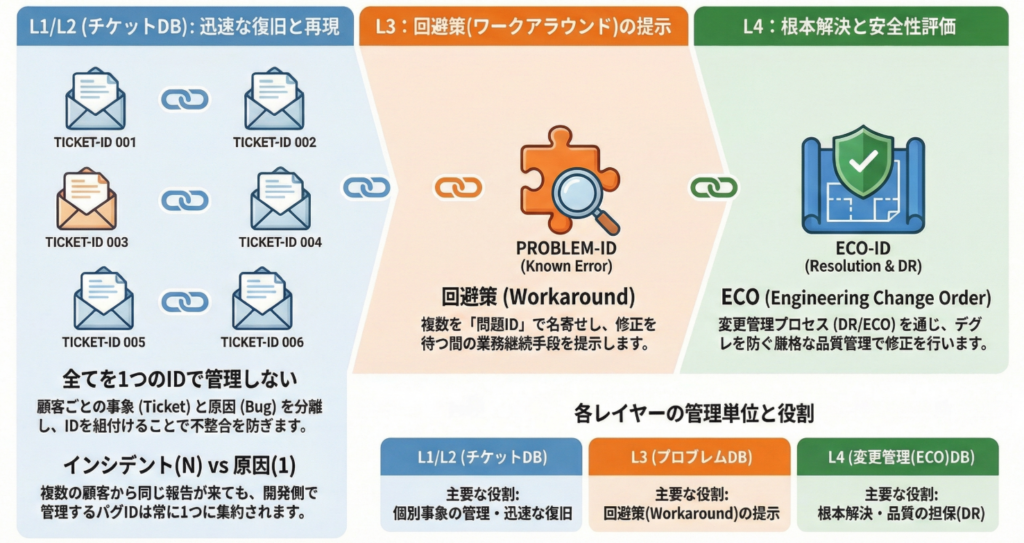
多くの現場では、顧客からの問合せも、開発への調査依頼も、製品の修正指示も、すべて1つの巨大な課題管理表(Excel)で行ごとに管理されています。しかし、これでは必ず破綻します。なぜなら、顧客の問合せ(N)と、製品のバグ(1)は、そもそも管理すべきデータベースが異なるからです。
本記事では、IT業界で標準的な、L1からL4までの保守のエスカレーション構造と、それを支えるID管理の分離について解剖します。
なぜ管理システムを分けるのか — 「N対1」の構造
すべての事象を1つのシート、1つのID体系で管理しようとすると、事象の管理なのか、問題の管理なのか混乱することがあります。 洗練された組織では、それぞれのレイヤーは異なるデータベース(DB)で管理され、異なる管理IDを持っています。
最大の理由は、問題が「N対1」の構造になるからです。
- チケットDB(L1/L2):事象を管理します。顧客A社とB社から同じ不具合報告が来た場合、チケットは2つ発行されます。
- バグDB(L3/L4):原因を管理します。A社とB社の事象が同じバグに起因する場合、開発側で管理するバグIDは1つです。
もしこれを1つのシートで管理すれば、「同じバグなのに2行ある」「片方を直したのにもう片方のステータスが変わっていない」といった不整合が必ず起きます。 だからこそ、このデータベースを明確に分離し、ID同士を紐付け(Link)することで管理する必要があるのです。
実例解剖 — L1からL4までの「ID連携プロセス」
では、具体的なIDの発行と連携の流れ(データフロー)を見てみましょう。 これはITIL 4などが提唱する概念(インシデント管理、問題管理、変更実現)を、実際のベンダー保守体制に落とし込んだ業界標準ともいえるエスカレーションモデルです。
L1-L4の呼び名は、ベンダーによって呼称が変わったりしますが、基本的な考え方は大きく違いません。
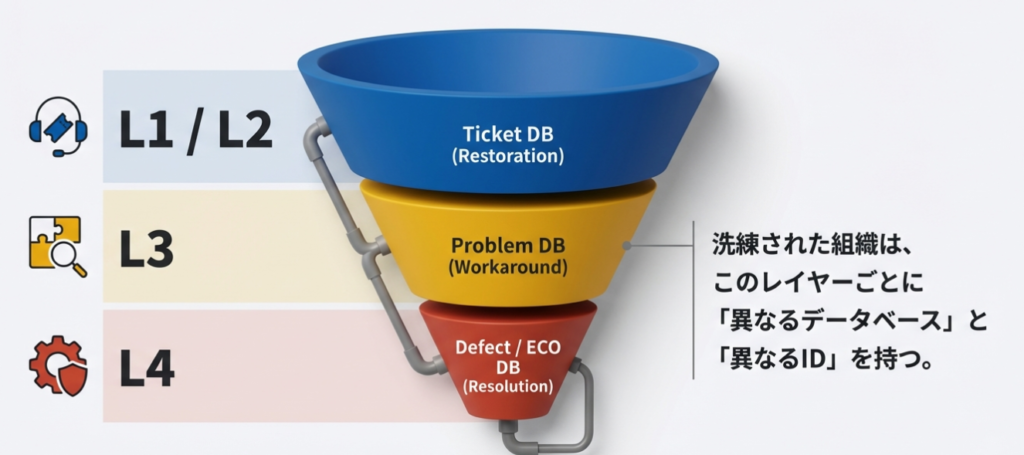
L1/L2:チケット管理(Ticket DB)
- 管理単位:問合せ(Case/Ticket)
- アクター:L1(エンドユーザー)、L2(代理店/パートナー)
- 役割:迅速な復旧とフィルタリング
顧客ごとにユニークなチケットIDが発行されます。ここでは「顧客Aで起きた」という個別事象が管理されます。
L2(代理店)の役割は、ただの取次ではありません。基本的には再現試験を行い、事象を確定させることです。 ただし、顧客環境に依存する複雑な問題で再現が困難な場合は、L3(ベンダー)と連携(Swarming)し、詳細ログと構成情報の確保をもってエスカレーション要件を満たすといった、柔軟な運用が求められます。
※L1/L2などの役割はエンドユーザー、代理店とベンダーとの保守契約によって内容は異なります。
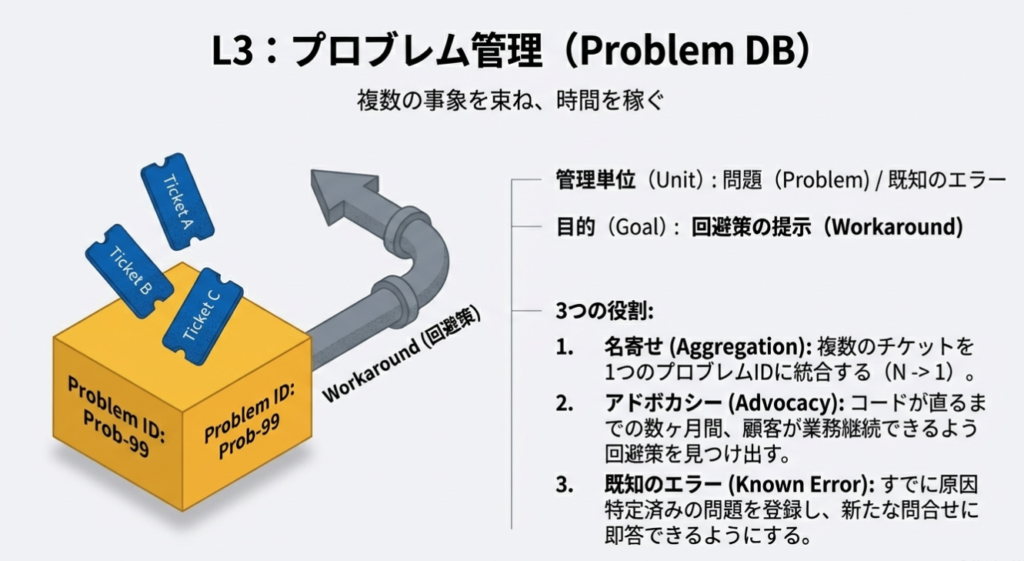
L3:プロブレム管理(Problem DB)
- 管理単位:問題(Problem) / 既知のエラー(Known Error)
- アクター:L3(ベンダーサポート / Advocate)
- 役割:回避策の策定(Workaround)
ここで初めて、複数の顧客から上がってきたチケットが、1つの「問題」として名寄せされます。
L3の重要な仕事は、開発のエスカレーションだけではありません。コードが直るまでの数ヶ月間、顧客が業務を継続できるように回避策(Workaround)を見つけ出し、提示することです。 また、すでに原因が特定されているが修正パッチ待ちの状態を既知のエラー(Known Error)として登録し、同じ問合せが来た際に即答できるようにします。
L4:変更管理(Defect/ECO DB)
- 管理単位:不具合/変更(Defect/ECO)
- アクター:L4(Escalation Engineer / Development Engineer)
- 役割:根本解決と安全性評価
※ECOは本来、ハードウェアの製造・生産工程に対する変更指示を指す言葉です。純粋なソフトウェア開発では「リリース判定」や「パッチ承認」など別の名称が使われることもあります。
原因が特定され、コード修正が必要と判断された場合、開発専用のデータベースで管理されます。
- 通常の変更(Normal Change): 修正コードは、新たなバグ(デグレ)を生まないよう、DR(デザインレビュー)などの厳格な品質プロセスを経てリリースされます。
- 緊急の変更(Emergency Change): ただし、業務停止(Severity 1)を伴う緊急事態においては、ホットフィックス(Hotfix)ルートが発動されます。これはスピードを最優先する特例措置です。
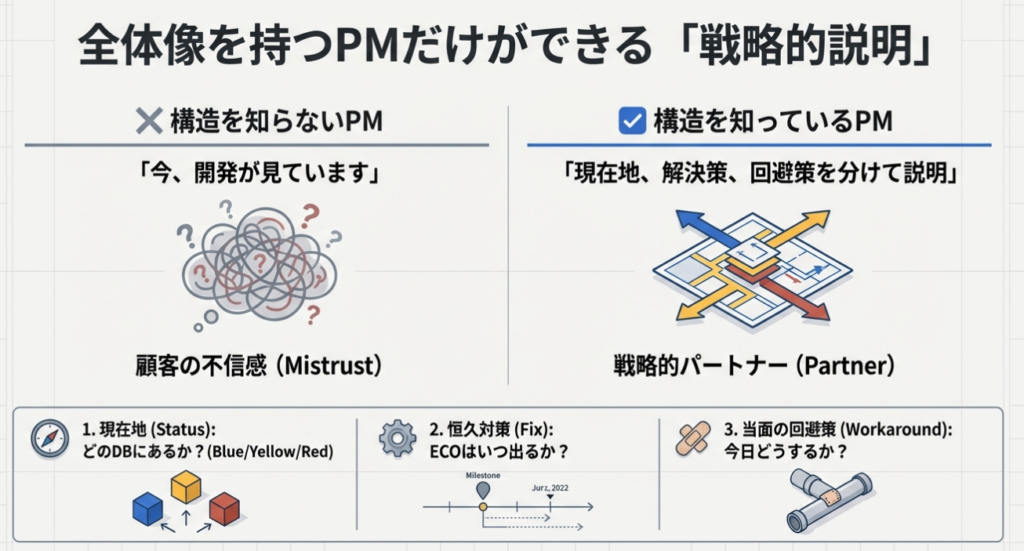
全体像を持つPMだけができる「戦略的説明」
このデータベースの分離とプロセスの連携が見えているPMは、顧客への説明力が劇的に変わります。
- 構造を知らないPM: 「今、開発が見ています(全部一緒くた)」 → 顧客はいつ終わるのか分からず、不信感が増大する。
- 構造を知っているPM: 「現在、御社のチケット(ID: Ticket-123)は、開発部門の問題管理DB(ID: Problem-456)に紐付けられ、原因は特定されました(既知のエラー化)。 現在、恒久対策コードは変更管理プロセスを経て次期パッチに含まれる予定ですが、それまでの間はL3チームが策定した回避策(ワークアラウンド)を適用することで、業務への影響を最小化できます。 ※もし業務停止レベルであれば、リスクを取って緊急変更(Hotfix)を要請しますので、その際は御社側での緊急適用検証(Verification)のご協力をお願いします」
現在地(Status)を正確に伝え、恒久対策(Fix)と当面の回避策(Workaround)、そして非常時の緊急ルート(Hotfix)を使い分けること。 そして、パッチが出たら終わりではなく、顧客環境での検証とクローズまでを見届けること。これこそが、プロジェクトを円滑に進めるPMの戦略です。
まとめ
「問題を管理する」とは、エクセルに行を追加し続けることではありません。 その事象が今、チケット(個別事象)なのか、プロブレム(共通課題)なのか、それともECO(製品変更)としてDRにかかっているのか。 この保守のエスカレーション構造を理解し、適切なDBに情報を格納してやることこそが、PMの本来の仕事なのです。
保守部門で専門的にこのような役割を「サービスマネージメント」実行する人を「サービスマネージャ」を呼びます。
しかし、プロジェクトを預かるPMにとっても、この「保守のエスカレーション構造」を理解し、適切なDBに情報を格納してやることは、円滑な進行のために不可欠なスキルなのです。
参考文献・リンク
- ITIL 4 Foundation: インシデント管理、問題管理の定義について参照
- Atlassian ITSM Guide: インシデント管理と問題管理の違い
- 段階的テクニカルサポート(Tiered Technical Support)
書籍
※本章はPRを含みます。

コメント